前面给出了二分检索树的定义,下图给出了关于保留字的一个子集的两棵二分检索树。
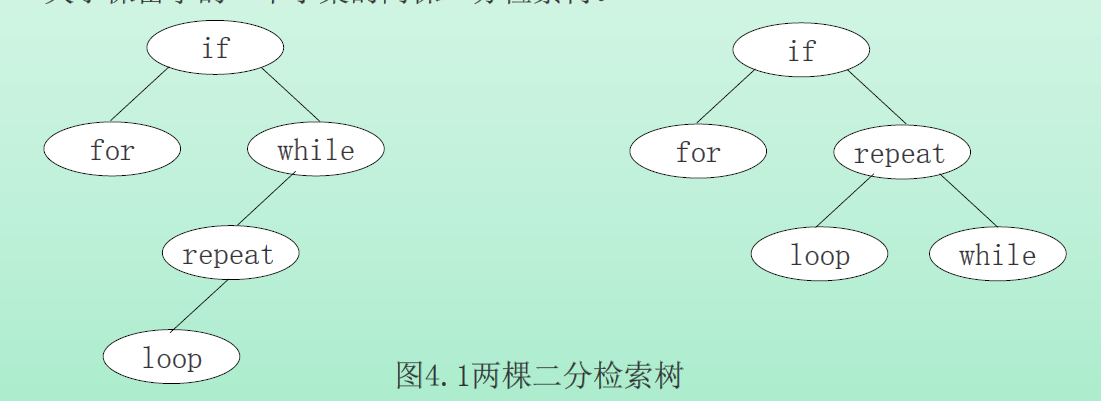
为了确定标识符x是否在一棵二分检索树中出现,将x先与根比较,如果X比根中标识符小,则检索在左子树中继续;如果x等于根中标识符,则检索成功地终止;否则检索在右子树中继续下去。上述步骤可以形式化为过程Search。
Line void Search (BinaryTree T,elemType x,int i) {//在二分检索树T上查找x,树的每个结点有三个信息段:LChild,IDent//和RChild。如果x不在T中,则置i=0,否则将i置成使得IDent(i)=x1 i = T;2 while(i!=0) {3 if(x=IDent[i] { return IDent[i]};//检索成功4 else5 if(x 已知一个固定的标识符集合,希望产生一种构造二分检索树的方法。可以预料,同一个标识符集合有不同的二分检索树,而不同的二分检索树有不同的性能特征。
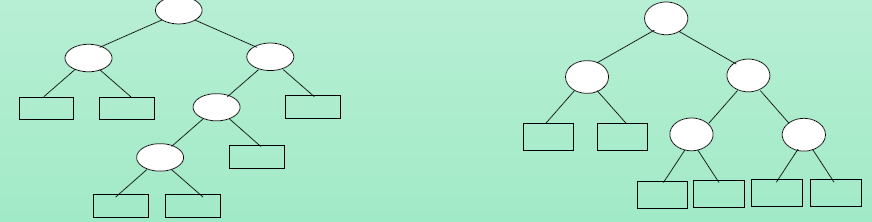
下面说说不成功检索的含义:为了得到二分检索树的成本函数,在这棵检索树的每一棵空子树的位置上加上一个虚构的结点,即外部结点,它们在图4.2中画成方框。所有其它结点是内部结点。如果一棵二分检索树表示n个标识符,那么正好有n个内部结点和n+1个外部结点。每个内部结点代表一次成功检索可能终止的位置。每个外部结点表示一次不成功检索可能终止的位置。
二分检索树的预期成本可用公式表示如下:
ΣP(i)*level(ai) + ΣQ(i)*(level(Ei)-l) 1≤i≤n 0≤i≤n定义标识符集(a1,a2,…,an)的最优二分检索树是一棵使(4.1)式取最小值的二分检索树。
如果T是最优的,则(4.2)式必定是最小值。进而COST(L)对于包含a1,a2,…,ak-1和E0,El,…,Ek-1的所有二分检索树必定是最小值,同理COST(R)也必定是最小值。
如果用C(i,j)表示包含ai+1,…,aj和Ei,…,Ej的最优二分检索树的成本,那么要让T是最优的,就必须有: COST(L) = C(0,k-1)和COST(R) = C(k,n) 而且应该选择k使得 P(k) + C(0,k-1) + C(k,n) + w(0,k-1) + w(k,n) 取最小值。因此,关于C(0,n)有
C(0,n) = min {c(0,k-1) + C(k,n) + P(k) + w(0,k-1) + w(k,n)} 0<k≤n将(4.3)一般化,对任何C(i,j)则有C(i,j) = min {C(i,k-1) + C(k,j) + P(k) + W(i,k-1) + W(k,i)}i<k≤j= min {C(i,k-1) + C(k,j)+W(i,j)} i<k≤j用下列步骤解(4.4)式可得C(0,n)。
首先计算所有使得j-i=1的C(i,j)(注意C(i,i)=0且W(i,i)=Q(i),0≤i≤n);接着计算所有使得j-i=2的C(i,j);然后计算j-i=3的所有C(i,j),等等。如果在这计算期间,记下每棵Tij树的根R(i,j),那么最优二分检索树就可以由这些R(i,j)构造出来。需要指出的是,R(i,j)是使(4.4)式取最小值的k值。
下面举个例子:找最小成本二分检索树
Line void OBST(P,Q,n) {//给定几个互异的标识符a1 <…